
Introduction
Financial institutions often rely on third parties to meet their model development needs, especially in the case of smaller institutions, or ones that are growing quickly. This motivation is simple: a third-party model developer allows the business line access to expertise and development skill that wouldn’t be available otherwise. However, a third-party model development resource doesn’t divest the institution or the model owner from the responsibility for understanding the model or checking the ongoing monitoring of performance. In the words of SR 11-7:
The widespread use of vendor and other third-party products—including data, parameter values, and complete models—poses unique challenges for validation and other model risk management activities because the modeling expertise is external to the user and because some components are considered proprietary. Vendor products should nevertheless be incorporated into a bank’s broader model risk management framework following the same principles as applied to in-house models, although the process may be somewhat modified.
In this post, we’ll discuss where the burden of proof lies for Model Risk Management (MRM) when managing third-party models.
Vendor Management
The first responsibility lies with the management of the vendors providing the third-party models, to determine if the vendor is a suitable partner. This goes past ensuring that the model owner will be getting a model that performs effectively, it includes ensuring that the vendor will provide:
- Timely support in the case of model failure.
- Evidence that the model has been certified by an independent party.
- Documentation and procedures surrounding the management of the data employed in the model.
- Model development documentation describing the conceptual framework of the model and the relevance of its development data.
- Outcomes analysis showing the performance of the model.
Additionally, the model owner must ensure that the data that is used to develop the model is relevant to the institution’s application needs:
If data and information are not representative of the bank’s portfolio or other characteristics, or if assumptions are made to adjust the data and information, these factors should be properly tracked and analyzed so that users are aware of potential limitations. This is particularly important for external data and information (from a vendor or outside party), especially as they relate to new products, instruments, or activities. [1]
For instance, an institution may check to ensure that a loan default prediction model was developed on a dataset with a similar distribution of FICO scores to the institution’s own portfolio.
It’s during the review and onboarding process that the institution has the largest ability to ensure that these questions are answered by the potential model vendor. Getting a satisfactory answer to these questions can aid the model owner in being able to justify the model’s performance.
What can be done to compensate now for a model missing a conceptual framework
One of the commonly mentioned issues with the use of statistical or machine learning models in banking is the possibility of “black-box” models. However, true “black-box” models are unusual – all models are built on a framework of mathematical and business assumptions. Even neural networks can be understood in this light and can be understood in terms of the activation functions used, the structure of the network, the cost functions, and the hyperparameters in the model. Software implementations of neural networks even include tools like TensorBoard to help the developer understand and explain its structure.
However, the modeling methodologies used for model risk management are generally less sophisticated that the framework described above. Often, a vendor model is a “black-box” not due to sophistication but due to information about the model not being provided by the vendor. However, the institution is still responsible for providing documentation and justification of the fitness of the model for its purpose. Without this information, the model owner will need to compensate for the lack of information by enhancing ongoing monitoring for the model.
While explicit information on the conceptual framework of the models may not be provided by the model developer, the model owner can help compensate for this missing information by introducing ongoing monitoring tests which focus on understanding the behavior of the model.
We’ve briefly described some common tests below.
Benchmark analysis
One way to gain an understanding of the reasonableness of a model’s behavior is by benchmarking it against well understood or validated frameworks. For instance, a model may be compared with a simple method such as logistic regression which can be used to validate the reasonableness of the behavior of the model. In the field of explainable machine learning, these are referred to as surrogate models.
By combining one or more benchmarks, the model owner can identify patterns including:
- Sensitivity/insensitivity to key variables.
- Comparative magnitude of inaccuracy.
- Tendency to over/underestimate results compared to other frameworks.
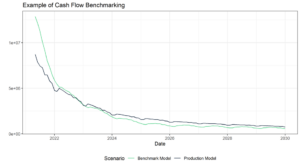
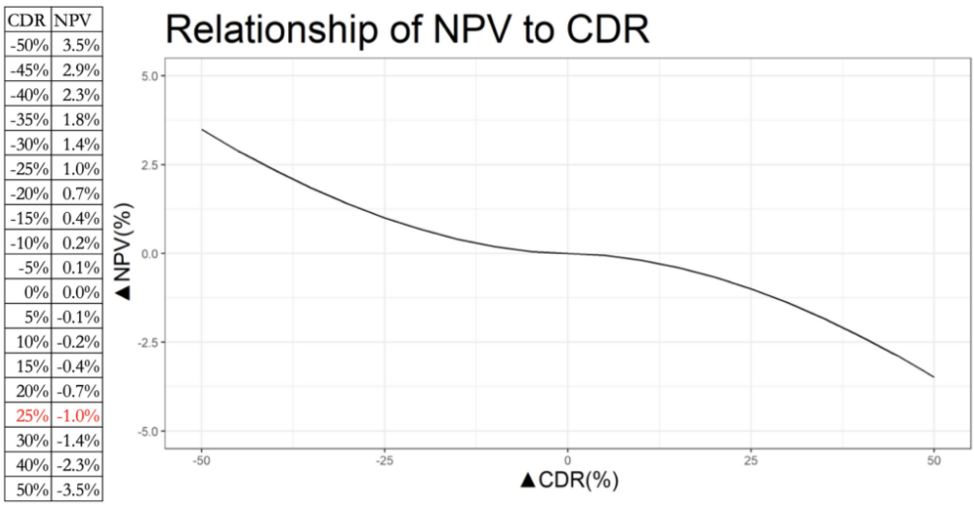
Sensitivity analysis
A powerful strategy for understanding a model’s performance is the use of sensitivity analysis. Using this strategy, the model owner tests the behavior of the model as different variable inputs for the model are varied. We’ve prepared an entire article on the value of sensitivity analysis that you can find here.
SHAP
SHapley Additive exPlanations (SHAP) are a powerful and intuitive method for understanding the output of machine learning models using techniques from game theory to determine the most influential variables for a model. These as well as other more advanced explainable machine learning techniques can be deployed to explore the behavior of more complex models.
Conclusion
In this post we’ve shown how SR 11-7 places the burden on showing the model’s fitness for use on the model owner. While an institution may outsource the development of a model to a third-party, it is still necessary to collect the normal proofs of its conceptual soundness, the relevance of the model’s development data, and its performance. If this is absent, the model’s behavior can’t be fully understood. This can’t be fully compensated for, however as discussed, the model owner can help justify the continuing use of the model by enhancing ongoing performance monitoring.
We at MountainView Risk & Analytics have both breadth and depth of experience identifying these weaknesses and making recommendations on how the institution can remove them or minimize their impact. We also review models and create performance monitoring frameworks utilizing the techniques and principles described in this article. If you have a model which needs to be documented, validated, or the creation of a performance monitoring plan, you can contact our team today or send us an e-mail at connect@mountainviewra.com to discuss your institution’s needs.
Written by Peter Caya, CAMS
 About the Author
About the Author
Peter advises financial institutions on the statistical and machine learning models they use to estimate loan losses, or systems used to identify fraud and money laundering. In this role, Peter utilizes his mathematical knowledge, model risk management experience to inform business line users of the risks and strengths of the processes they have in place.

